
| Ԕ����Ϣ |
FCGEC������-�㽭��W |
| ���� ��Դ���A̩�Cȯ �r�g��2023/5/19 |
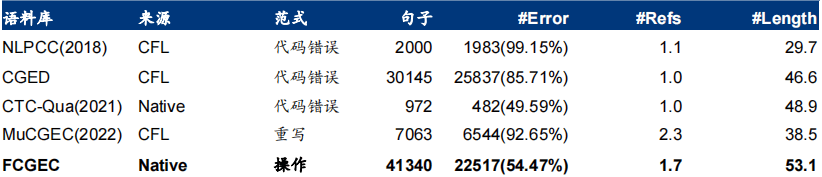
FCGEC ���������� 2022 �����㽭��W���A���ϰl����FCGEC ���ڙz�y���R�e�ͼm�� �Z���e�`����һ���˹���ע�Ķ������Z�ώ죬�� 41,340 �����ӽM�ɣ���Ҫ���Թ����WУ�Z �Ŀ�ԇ�е��x���}��
|
| �������D�d���ij��ڂ��f������Ϣ֮Ŀ�ģ�������ζ��ٝͬ���^�c���C���������������݃H�������������֙࣬Ոϵ�h������ |
| ���]��Ϣ |
|
DRCD������-�_�_
DRCD���������ęC����x���┵����,�������� 2108 ƪ�S���ٿ����µ� 10014 ���������ע������ɵ� 33,941 ��������
Ape210K������-Գ�o�� AI Lab
Ape210K��һ���� �Ĵ�Ҏģ��ģ���S���Ĕ��W���~���}������,���� 210K ���Ї�С�Wˮƽ�Ĕ��W���},�����S��𰸺͵ó�������ķ���ʽ
Math23K������-��Q���W���}������
Math23K�Ǟ��Q���W���}�������Ĕ�����,�����������ھ������Wվ��ץȡ�� 6 �f�������Ĕ��W���~���},����С�W �������Ĕ��W�����}
CAIL2018������ �Ї����ɔ���
CAIL2018�ǵ�һ�������ЛQ�A�y�Ĵ�Ҏģ�Ї����ɔ�����,��� ���Ї��������Ժ���� 260 �f�����°���,���m�õķ��ɗl��ָ�غ����ڽM��
�Ї��_Դ���Z��ģ�͔����� WuDaoCorpora������
WuDaoCorpora���������� 20 ��NҎ�t�� 100TB ԭʼ�W퓔�������ϴ�ó���K������,ע���[˽������Ϣ��ȥ��,֧�ֶ��I���AӖ��ģ�͵�Ӗ��
�Ї��_Դ���Z��ģ�͔����� DuReader������
DuReader��һ����Ҏģ���_�������ęC����x���┵����,���}���ęn���ڰٶ������Ͱٶ�֪��,�����ք����ɵ�,��200K���},420K�𰸺�1M�ęn�M��
�Ї���ģ�B��ģ�͔���������
����M6��ģ�ͅ���Ҏģ�_�� 1000 �|,�������������Ķ�ģ�B�AӖ�������� M6-Corpus;�ٶ�ERNIE-ViLG��ģ�ͅ���Ҏģ�_�� 100 �|
�Ї��������Z��ģ�͔���������
�ٶ�Plato-XL��ģ���AӖ���Z��Ҏģ�_ǧ�|�� token,ģ��Ҏģ���_ 110 �|����;�A��P�Ŵ�ģ���_Դ�˱P�Ŧ��ͱP�Ŧ�������ɂ��汾 |
| �����\ݔ�C���� |
| AGV�o���\ݔ�C����-����� |
| AGV�o���\ݔ�C����-�˜ʰ� |
| AGV�o���\ݔ�C����-����棨�k����|�� |
| AGV�o���\ݔ�C����-؛�ܰ棨�k����|�� |
| AGV�o���\ݔ�C����-؛�ܰ棨���治�P䓲��|�� |
| AGV�o���\ݔ�C����-�_�Ű� |
| �ИI�ӑB |
