
| Ԕ����Ϣ |
Ӗ���������� InstructGPT �������A�������µĪ���ģ�� |
| ���� ��Դ���A̩�Cȯ �r�g��2023/5/10 |
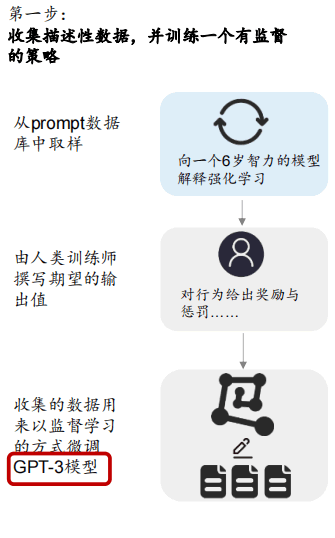
�AӖ��֮��GPT-4 �������c InstructGPT ͬ�ӵķ����M�� RLHF��OpenAI �ȏ����ע�T̎�ռ���ʾ�������o��һ��ݔ�룬��ʾģ�͑�ԓ���푑���������ģ�͵�ݔ�������M���������o��һ��ݔ��ׂ͎�ݔ������ݔ���ĺõ����M������ Ȼ��������²��E�� 1�������ռ������˹���ע��ʾ������ʹ�ñO���W����SFT����ģ�M��ʾ�е��О����{ GPT-4��
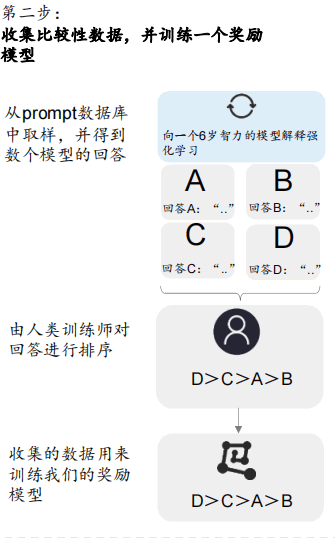
2��ʹ���ռ���������������Ӗ������ģ�ͣ�RM����ԓģ���A�y��ע�T���o��ݔ�� ��ƽ��ƫ�ã�
3��ʹ�ê���ģ�ͺ͏����W�����e�� PPO �㷨�������� GPT-4 SFT ģ�͡�
|
| �������D�d���ij��ڂ��f������Ϣ֮Ŀ�ģ�������ζ��ٝͬ���^�c���C���������������݃H�������������֙࣬Ոϵ�h������ |
| ���]��Ϣ |
|
GPT-4��һ�����c�ǘ��������A�y����ȌW���ї�
�����A�y����ȌW���ї�,�܉�ͨ�^Ӌ��� GPT-4 Ӌ������1000x-10000x��x ����������ģ������, �A�y������ȫ�w��GPT-4 ������
�ı����ɣ�NLP��Ҫ�΄�֮һ�W�j���ɷ�������څ��
Transformer�ܘ�����Self-attention��ע�����C�ƿ�ȡ��RNN,�ķ��Z�Եı�ʾ���������������ı�,�����˂��yRNN��ˮƽ����Ă���
ChatGPT�lչչ�����v�����AI���� �M����չ����߅��
hatGPTģ�ͻ���RLHF���AӖ���C�ƌ��Mһ������ģ�ͷ����Ĝʴ_�Ժ͕rЧ��,�C����AIGC������صĿ������c���M��,��������đ�������
ChatGPT��������֧�Ό��F���������в������M��
1 ģ��Ӗ��Ч�����;2 Ӗ��ģʽ����ͨ����,����Ч������;3 �����ʴ_������;4 ���Ծܽ^�Ñ��IJ��m��Ո��;5 �܉���J�e�`,�������_��ǰ��
����RLHF���㷨����,����GPTģ����
ͨ�^����ģ�ͮa�����ݔ���Y����,��ԓ�Y����ģ�ͅ����M�е����c����,�����|����ChatGPTģ��,������Codexģ������������������
��AlphaGo��ChatGPT��AI���g�lչߵ�AGI֮�T
ChatGPT�����ք����c�Z�Խ����ȷ�������������@ϲ,һ���̶��ό��F�����ͬ������,�����x��Ч��,���FAGI���п�����,����AI�lչǰ��
�̘I����ͨ�^���� GPT-4 ������������
�Ԅӌ��Ñ�ݔ�����Ȼ�Z���D�����ԃ SQL;֧�ָ����Ñ���D�Ԅ������Զ��x�Ŀ�ҕ���Y��;�Y�Ͽ�ҕ���ĈD���M�к������� �Ԅ����ɿɽ���ʹ�õĕ�����
����ȫ������ AI ���g�wϵ���γ� IaaS��PaaS �� MaaS ���Ӽܘ�
ħ����^ģ�Ϳ����_ 800+,MaaS �ĺ����nj�ģ���������a����ҪԪ��,��Ч֧��ģ�͵���������,�_�l���ܿ��ٲ��Ҳ�ʹ��ģ��,����ģ��ʹ���T�� |

| �����\ݔ�C���� |
| AGV�o���\ݔ�C����-����� |
| AGV�o���\ݔ�C����-�˜ʰ� |
| AGV�o���\ݔ�C����-����棨�k����|�� |
| AGV�o���\ݔ�C����-؛�ܰ棨�k����|�� |
| AGV�o���\ݔ�C����-؛�ܰ棨���治�P䓲��|�� |
| AGV�o���\ݔ�C����-�_�Ű� |
| �ИI�ӑB |
